First steps
After going through the Installation section and having installed all the Operators, you will now deploy a Druid cluster and it’s dependencies. Afterwards you can verify that it works by ingesting example data and subsequently query it.
Setup
Three things need to be installed to have a Druid cluster:
-
A ZooKeeper instance for internal use by Druid
-
An HDFS instance to be used as a backend for deep storage
-
The Druid cluster itself
We will create them in this order, each one is created by applying a manifest file. The Operators you just installed will then create the resources according to the manifest.
ZooKeeper
Create a file named zookeeper.yaml with the following content:
---
apiVersion: zookeeper.stackable.tech/v1alpha1
kind: ZookeeperCluster
metadata:
name: simple-zk
spec:
image:
productVersion: 3.9.2
servers:
roleGroups:
default:
replicas: 1
---
apiVersion: zookeeper.stackable.tech/v1alpha1
kind: ZookeeperZnode
metadata:
name: simple-druid-znode
spec:
clusterRef:
name: simple-zk
---
apiVersion: zookeeper.stackable.tech/v1alpha1
kind: ZookeeperZnode
metadata:
name: simple-hdfs-znode
spec:
clusterRef:
name: simple-zkThen create the resources by applying the manifest file
kubectl apply -f zookeeper.yamlHDFS
Create hdfs.yaml with the following contents:
---
apiVersion: hdfs.stackable.tech/v1alpha1
kind: HdfsCluster
metadata:
name: simple-hdfs
spec:
image:
productVersion: 3.3.6
clusterConfig:
dfsReplication: 1
zookeeperConfigMapName: simple-hdfs-znode
nameNodes:
roleGroups:
default:
replicas: 2
dataNodes:
roleGroups:
default:
replicas: 1
journalNodes:
roleGroups:
default:
replicas: 1And apply it:
kubectl apply -f hdfs.yaml
Druid
Create a file named druid.yaml with the following contents:
---
apiVersion: druid.stackable.tech/v1alpha1
kind: DruidCluster
metadata:
name: simple-druid
spec:
image:
productVersion: 28.0.1
clusterConfig:
deepStorage:
hdfs:
configMapName: simple-hdfs
directory: /data
metadataStorageDatabase:
dbType: derby
connString: jdbc:derby://localhost:1527/var/druid/metadata.db;create=true
host: localhost
port: 1527
tls: null
zookeeperConfigMapName: simple-druid-znode
brokers:
roleGroups:
default:
replicas: 1
coordinators:
roleGroups:
default:
replicas: 1
historicals:
roleGroups:
default:
replicas: 1
middleManagers:
roleGroups:
default:
replicas: 1
routers:
roleGroups:
default:
replicas: 1And apply it:
kubectl apply -f druid.yaml
This will create the actual druid instance.
This Druid instance uses Derby (dbType: derby) as a metadata store, which is an interal SQL database. It is not persisted and not suitable for production use! Consult the Druid documentation for a list of supported databases and setup instructions for production instances.
|
Verify that it works
Next you will submit an ingestion job and then query the ingested data - either through the web interface or the API.
First, make sure that all the Pods in the StatefulSets are ready:
kubectl get statefulsetThe output should show all pods ready:
NAME READY AGE simple-druid-broker-default 1/1 5m simple-druid-coordinator-default 1/1 5m simple-druid-historical-default 1/1 5m simple-druid-middlemanager-default 1/1 5m simple-druid-router-default 1/1 5m simple-hdfs-datanode-default 1/1 6m simple-hdfs-journalnode-default 1/1 6m simple-hdfs-namenode-default 2/2 6m simple-zk-server-default 3/3 7m
Then, create a port-forward for the Druid Router:
kubectl port-forward svc/simple-druid-router 8888 > /dev/null 2>&1 &
Ingest example data
Next, we will ingest some example data using the web interface. If you prefer to use the command line instead, follow the instructions in the collapsed section below.
Alternative: Using the command line
If you prefer to not use the web interface and instead interact with the API, create a file ingestion_spec.json with the following contents:
{
"type": "index_parallel",
"spec": {
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "http",
"uris": [
"https://druid.apache.org/data/wikipedia.json.gz"
]
},
"inputFormat": {
"type": "json"
}
},
"dataSchema": {
"granularitySpec": {
"segmentGranularity": "day",
"queryGranularity": "none",
"rollup": false
},
"dataSource": "wikipedia",
"timestampSpec": {
"column": "timestamp",
"format": "iso"
},
"dimensionsSpec": {
"dimensions": [
"isRobot",
"channel",
"flags",
"isUnpatrolled",
"page",
"diffUrl",
{
"type": "long",
"name": "added"
},
"comment",
{
"type": "long",
"name": "commentLength"
},
"isNew",
"isMinor",
{
"type": "long",
"name": "delta"
},
"isAnonymous",
"user",
{
"type": "long",
"name": "deltaBucket"
},
{
"type": "long",
"name": "deleted"
},
"namespace",
"cityName",
"countryName",
"regionIsoCode",
"metroCode",
"countryIsoCode",
"regionName"
]
}
},
"tuningConfig": {
"type": "index_parallel",
"partitionsSpec": {
"type": "dynamic"
}
}
}
}Submit the file with the following curl command:
curl -s -X 'POST' -H 'Content-Type:application/json' -d @ingestion_spec.json http://localhost:8888/druid/indexer/v1/taskContinue with the next section.
To open the web interface navigate your browser to https://localhost:8888/ to find the dashboard:
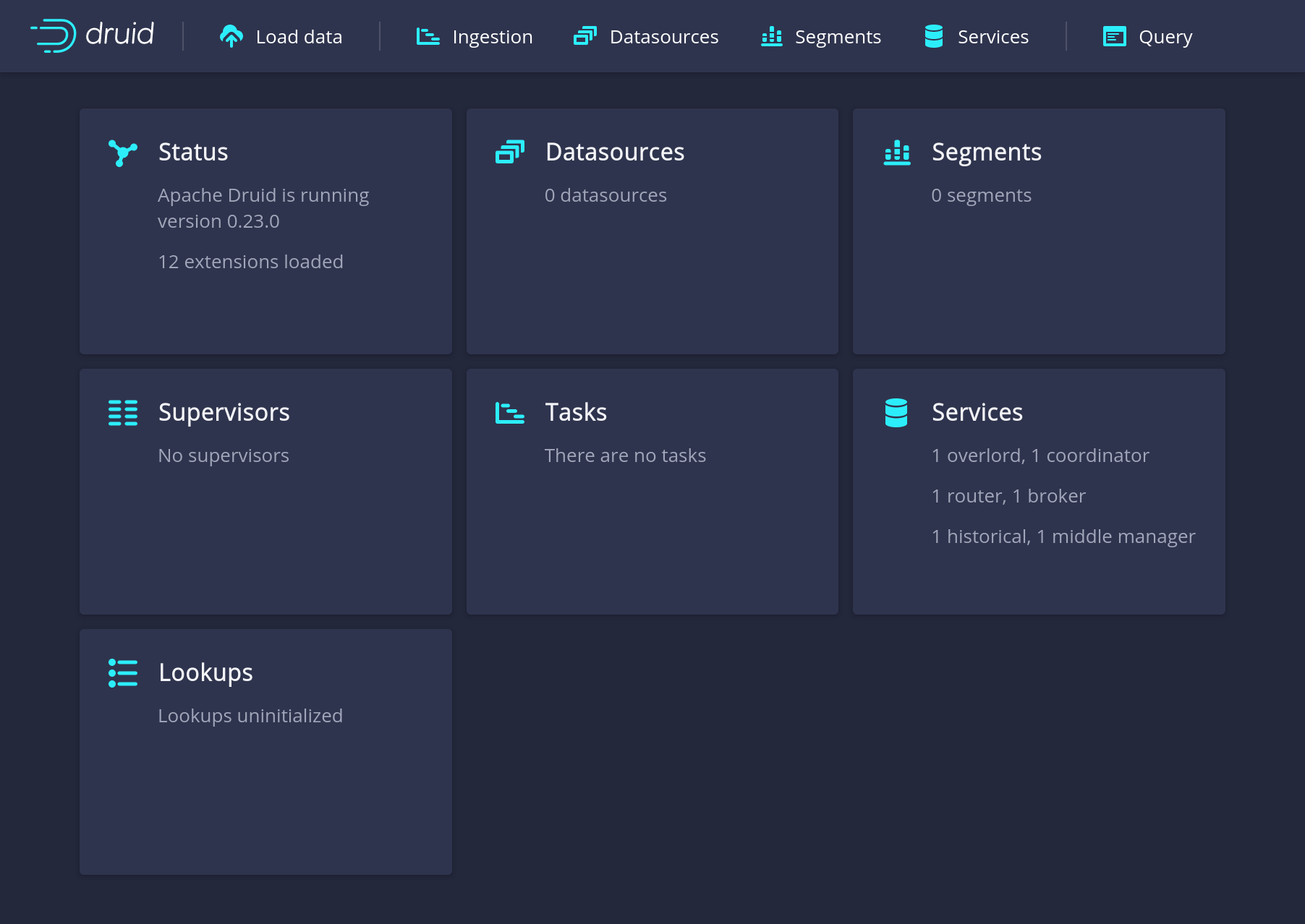
Now load the example data:
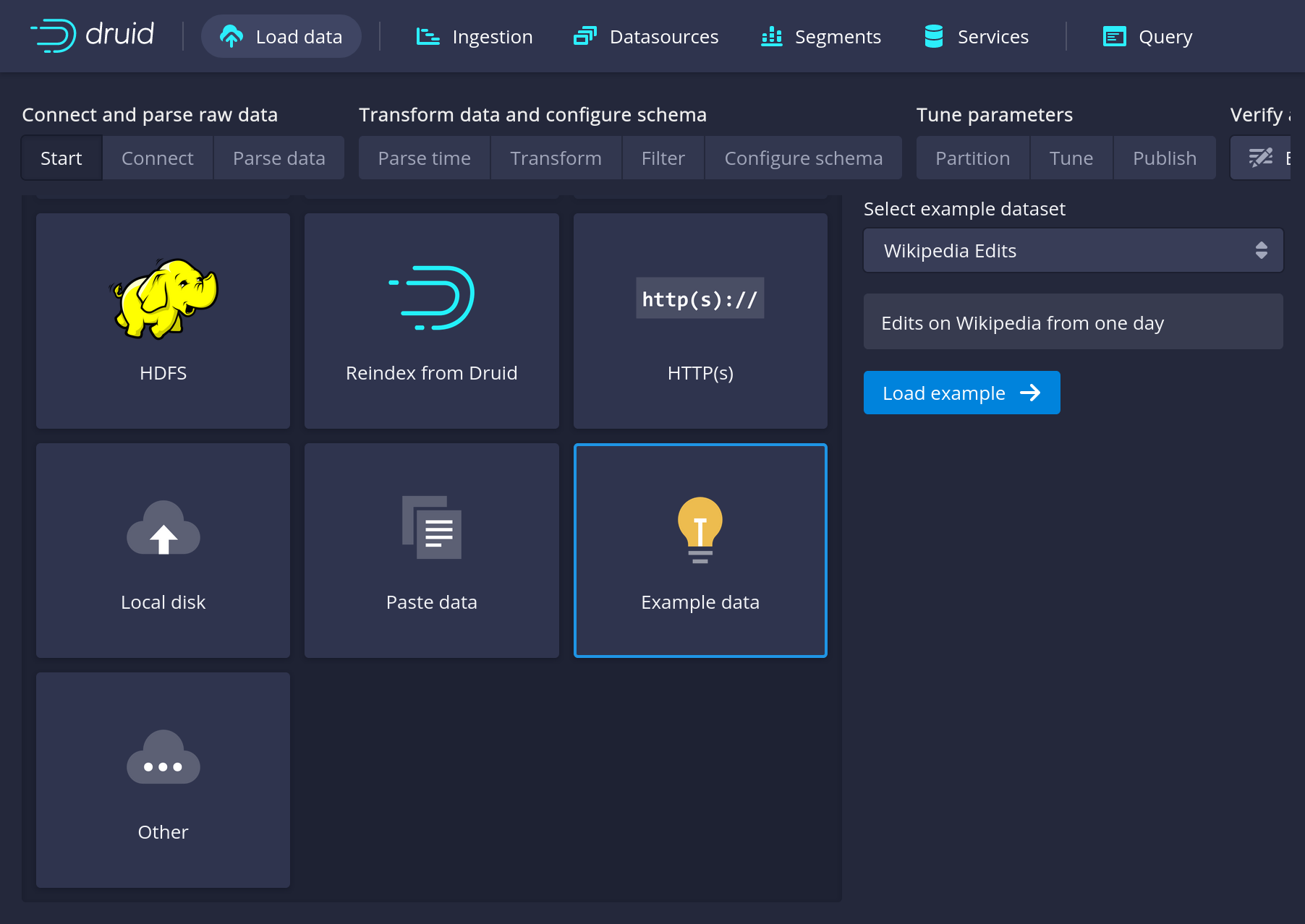
Click through all pages of the load process. You can also follow the Druid Quickstart Guide.
Once you finished the ingestion dialog you should see the ingestion overview with the job, which will eventually show SUCCESS:
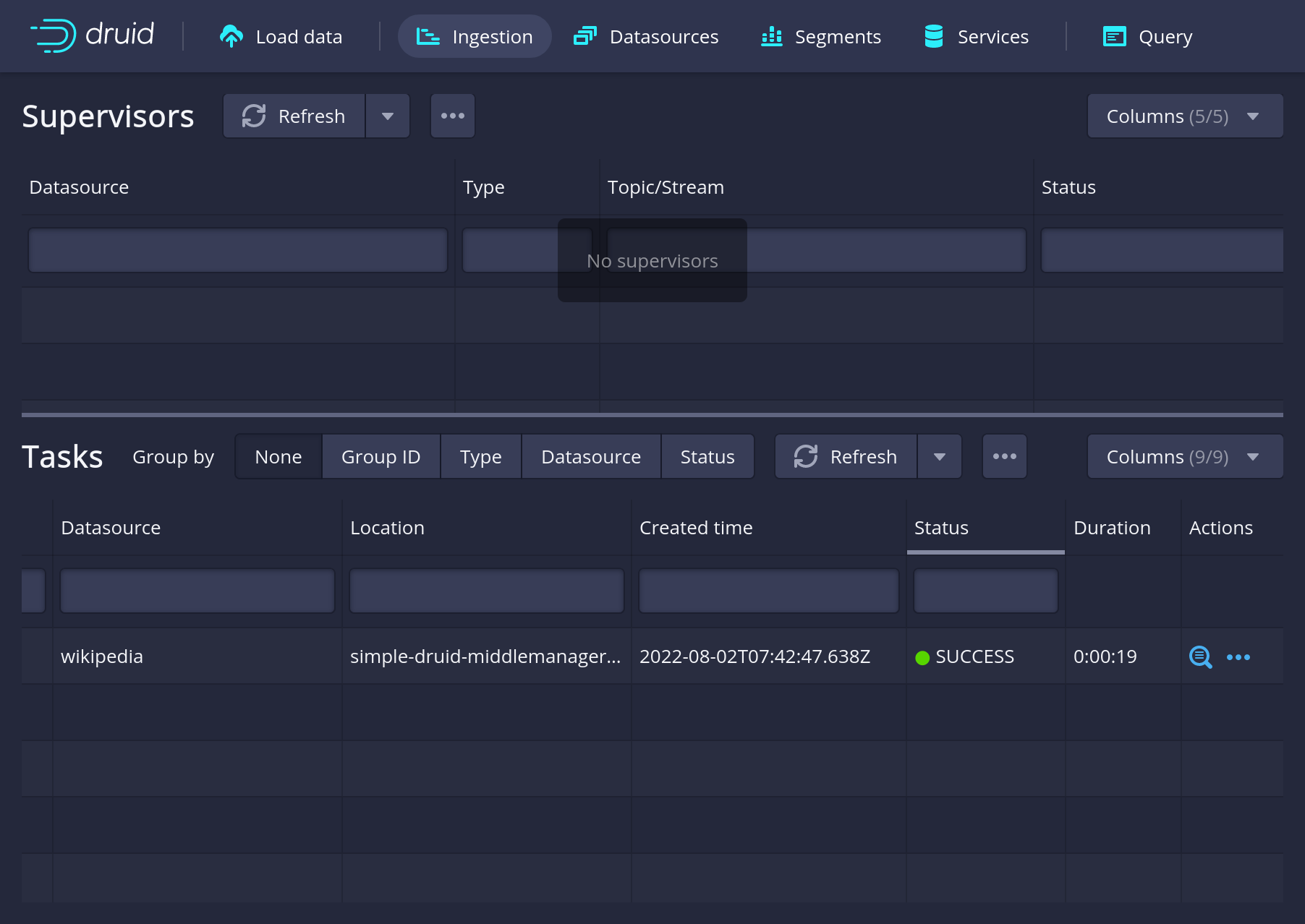
Query the data
Query from the user interface by navigating to the "Query" interface in the menu and query the wikipedia table:
Alternative: Using the command line
To query from the commandline, create a file called query.json with the query:
{
"query": "SELECT page, COUNT(*) AS Edits FROM wikipedia GROUP BY page ORDER BY Edits DESC LIMIT 10"
}and execute it:
curl -s -X 'POST' -H 'Content-Type:application/json' -d @query.json http://localhost:8888/druid/v2/sqlThe result should be similar to:
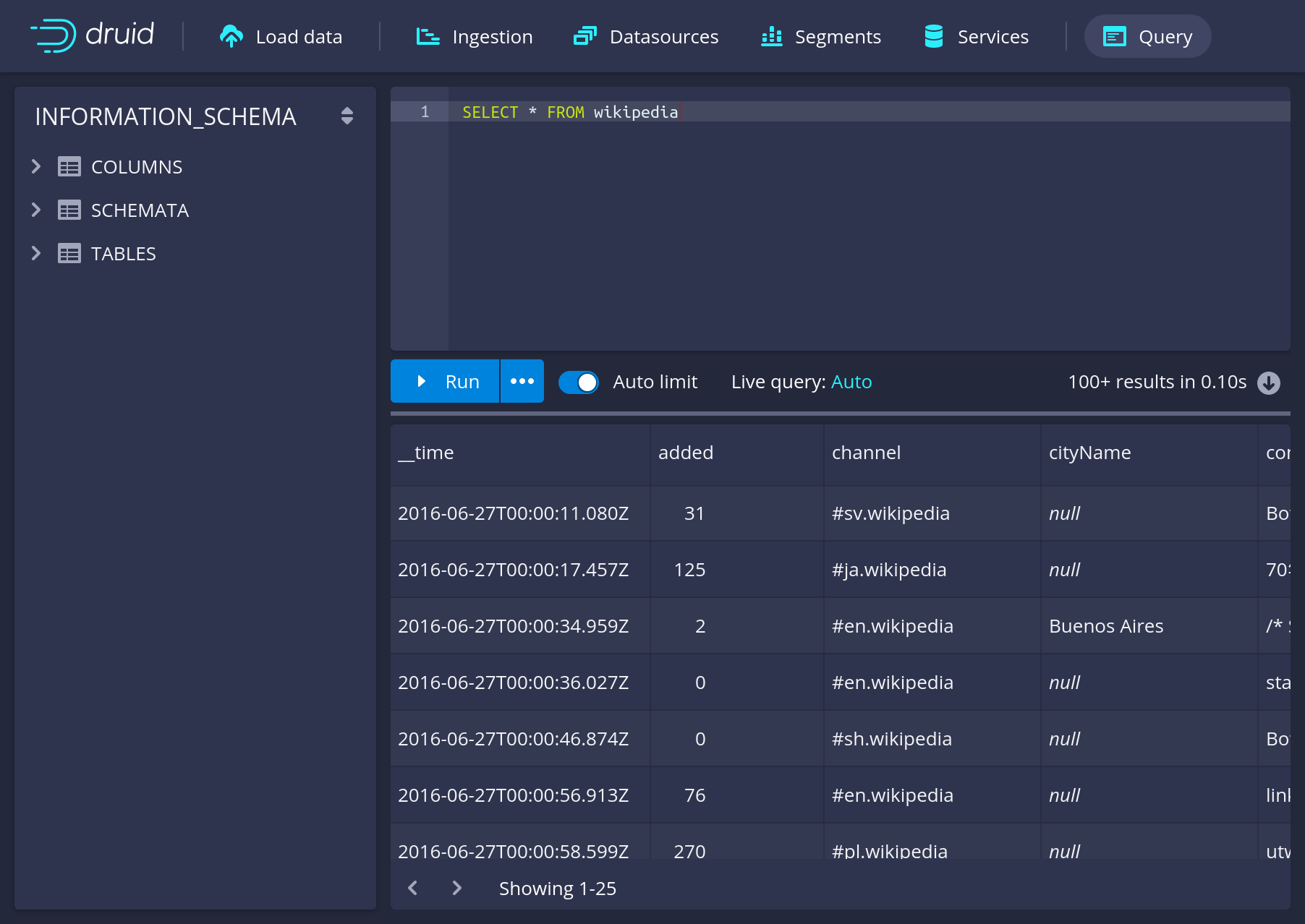
Great! You’ve set up your first Druid cluster, ingested some data and queried it in the web interface.
What’s next
Have a look at the Usage guide page to find out more about the features of the Operator, such as S3-backed deep storage (as opposed to the HDFS backend used in this guide) or OPA-based authorization.